Additional funding and support from the Prof. Dr. Wuytack Fund and the Department of Pure Mathematics and Computer Algebra.
| Benjamin De Leeuw |
| prof. dr. Albert Hoogewijs |
| Gent University |
| Belgium |
In the shared memory models, we see two approaches. On the one hand, there are processor centric models, where the main issue consists of the cache coherency of every processor in a distributed system. On the other hand we have shared memory centric models. By this the main issue is the constraining effect on the state space of the memory locations.
A memory model for a multithreaded or distributed system is a means to reason about memory actions (e.g. reads and writes) as they appear in a program execution. The main question that is tackled is which value each read of a memory location may return at a specific point in the program. This information makes it possible to reason about which compiler or hardware transformations are allowed without changing the meaning of the program.
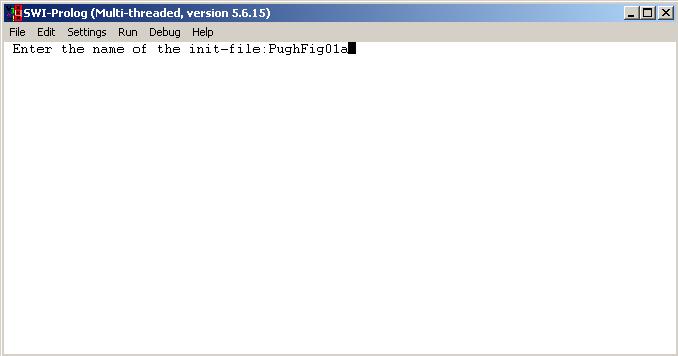
On this page we provide a Prolog implementation to understand and verify memory configurations in an intuitive way. Prolog turns out to be an excellent choice of language to describe the shared memory behavior of distributed systems in.
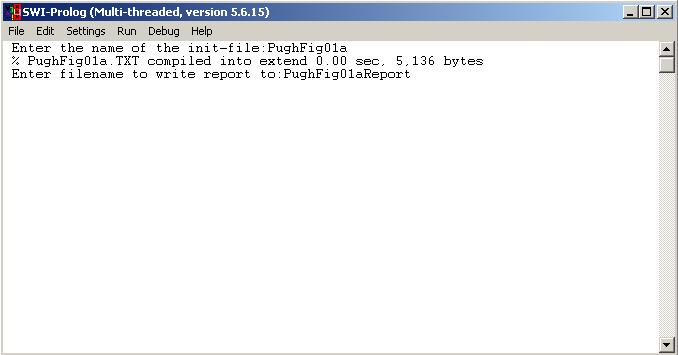
We also provide some example memory configurations. These are the examples, used in JSR-133, an official Java service request, which remedies the flawed memory model and thread specification of the Java 2 specification. The examples are used to illustrate certain classes of problems. Look up the source document for more information here. To download all example configurations, click here. A detailed list of examples can be found here.
A user guide to the program memmod.exe v1.00 is available here.
We plan on releasing the prolog code of the program, as soon as it has been cleared of bugs and other compromising material that might make us look stupid. We hope this will be pretty soon.
We want to make the workings of memmod.exe v1.00 available as a pre-compilation processor for distributed specifications in Java. When a Java program is compiled during developement, we want to observe this process, and log the memory behavior in a memory configuration file. This file can be consulted by our engine and be translated in a report file. The information in this report can be coupled back to the developement environment, and be made available to the distributed programmer. The information in the report file can also be used to guide different program refactorings. We will tend to provide an Eclipse plugin which supports and implements these operations.
|
| Figure 1 |
 |
| Figure 2 |
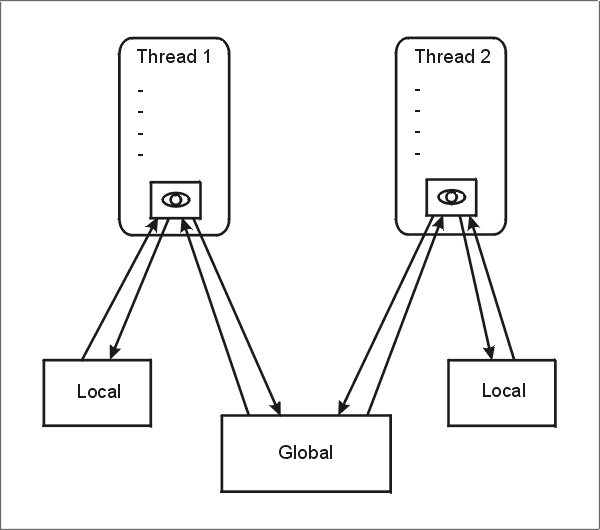
In memory models, we would like to talk about some kind of working value for each read and write instruction. This value, is the value seen from some viewpoint. The predominant ability of calculation units in distributed systems, is that they can see different values, at some measurable point in the execution of the whole system. If they couldn't, it would not be a distributed system. Every memory instruction in our new language, has such a working value. This value can only be influenced by instructions (reads for example) appearing in the same thread and vice versa. We model this working value as a local register (lr), which denotes the current working value, for each thread, at every measurable point in the execution. Figure 3 displays this architecture, with lr depicted as the "eye" of every thread or process. Local and global memory locations are also shown.
 |
| Figure 3 |
Every memory instruction has its own id. These ids are grouped and ordered in threads, using the directive
program_order([i1,i2,i3,i4,...]). program_order([i3,i21,i22,i23,...]).
in the configuration file. This order denotes the so called program order (po). For a distributed system, this is always a partial order. In the example above, i1 comes before i2,i2 before i3,i3 before i4, and also i3 before i21, i22 and i4 are not ordered to eachother, and so on.
Our action language is specified by a context free grammar, which can be found here. The action semantics are all related to corresponding constructs in contemporary object-oriented programming languages like Java. The meaning of the actions is straightforward, and is displayed here.
The fact that locks and unlocks, and if-fi constructs are properly paired and nested, is not something we are concerned with. A standard compiler checks these things, so why would we repeat them. We therefore do no additional testing on following two ordering constructs in the configuration file:
lock_pair([(i1,i3),(i2,i4),...]). if_pair([(i6,i8),(i10,i12),...]).
The correctness of these constraints is taken for granted. Both can be derived from the compilation process, or by a manual effort.
For every lock action, one or more most recent unlock (mru) actions are specified by the directive
synchro_order([(i3,i20),...]).
This is a form of synchronization, which can be determined at execution time only, when the different threads are scheduled. The po combined with
the synchronization order (so) must also be a valid partial order relation. Our program reports it, when this is not the case. For more information
on the usage of the configuration file, see the examples.
Grammar Specification
We use a CFG to formally define the content of a memory configuration textfile:
< memory_instruction > := mem(< id >,< thread >,< type >,< data >). < type > := re | wr | lo | un | cr | rc | if | fi | du < variable > := < variable_name > | a(< variable >,< offset >) < data > := < variable > | < value > | < guard > | null < value > := v(< content >) | c(< object >,< default_list >) < guard > := < data > | n(< data >) < default_list > := LIST of (< offset >,< content >) < id >,< thread >,< variable_name >,< object >,< offset >,< filename > := SET of ATOM < content > := SET < module_name > := :- module(extend, [mem/4,program_order/1,if_pair/1,lock_pair/1,synchro_order/1]). < program_order > := program_order(< id_list >). < if_pair > := if_pair(< id_pair_list >). < lup > := lock_pair(< id_pair_list >). < synchronization_order > := synchro_order(< id_pair_list >). < id_list > := LIST of < id > < id_pair_list > := LIST of < id_pair > < id_pair > := (< id >,< id >) < module > := < module_name > < memory_instruction > * < program_order > * < if_pair > < lup > < synchronization_order >A legal configuration file, is a textfile, which contains one < module >.
Not all combinations of (< type >,< data >) in < memory_instruction > are allowed. In this table we sum up the different possibilities and their semantics.
| (< type >,< data >) | Semantics |
|---|---|
| (re,< variable >) | read a local or global variable in lr |
| (wr,< variable >) | write the value of lr to a local or global memory location |
| (lo,< variable_name >) | lock access for a variable |
| (un,< variable_name >) | unlock access for a variable |
| (cr,< value >) | create the given value in lr |
| (rc,c(< object >,< default_list >)) | refactor an object but leave lr unchanged |
| (if,< guard >) | is fulfilled if at least one value of lr matches the guard |
| (if,n(< guard >)) | is fulfilled if at least one value of lr doesn't match the guard |
| (fi,null) | closes an if construct |
| (du,null) | nop, does nothing |
Thread's start and stop synchronization is displayed by outgoing and incoming arrows respectively, next to the < memory_instruction >.
Most recent writes are displayed by sets next to incoming arrows right of the < memory_instruction >.
Examples
Following examples are from JSR-133. They all illustrate a specific problem
with naive memory models. We translated these examples to our system, and produced the different reports. We named them, using the expression
PughFigNNx, where NN stands for the number of the
respective figures of the JSR-133 document, and x is an optional letter. They are useful to learn
what kinds of problems
are present in naive memory models, and show that our system can correctly handle the different memory constraints. At some points our
developed language allows for a different flavour of expressivity in comparison to the language used in JSR-133. See for example PughFig04a.txt, PughFig04b.txt, PughFig19a.txt and PughFig19b.txt.
There is also a class of complex inference and security problems discussed in JSR-133, which we discarded in favour of model simplicity. See for example PughFig16a.txt, PughFig16b.txt, PughFig16c.txt, PughFig17.txt and PughFig18.txt.
Here is the complete list: