The main class is GveCalc. It can be used both as an applet and as an application. Note the debuglevel constant (which is a copy of Part.debuglevel). The higher the value of this constant, the more debug messages are generated. A zero value indicates no debug output at all. Presently, it is advisable to keep this constant set to a non-zero value :-) (The current value is 100)
It contains some standard mathematical operators.
All nodes of the syntax tree are subclasses of Part. A syntax tree is encapsulated in the Formula class. Strictly speaking, we could do without Formula and use its top Part. But since a lot of operations can change that top part (e.g. replacing, rotating), we chose to introduce the Formula class, so the changes of top part are tracked automatically. So, in order to replace a part in a syntax tree, one does not call a replace() method of Part, but asks the Formula to do it:
The actual replacement is done behind the screens by the Part.replaceChild() method.
As we said before, a Part represents a node of a syntax tree. In gve.calc.formula, some standard Part subclasses are defined: Identifier, Operator, PrefixUnaryOp, etc. The Part is not responsible for displaying the syntax tree on the screen. Instead, a separate tree is built, consisting of standard AWT Components, closely mimicking the Part tree. These Components display the formula and modify it when the user presses keys or clicks with the mouse. In Model-View-Controller paradigm speak, the Part tree is the Model and the View and Controller are implemented by the Component tree. More details about this later.
The Identifier class assumes that identifiers are of the following form:
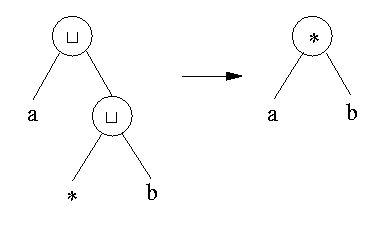
So, tokenizing is done by the Identifier class: all tokens are put next to each other, separated by Spaces. And parsing is done by checking, whenever a new Space operator is introduced in the syntax tree, whether we see an operator surrounded by spaces.
It is clear that sometimes, the syntax tree has to be rotated. Suppose the user just typed a*b and types +c. Then, the system recognizes a + operator, but it has to be rotated:
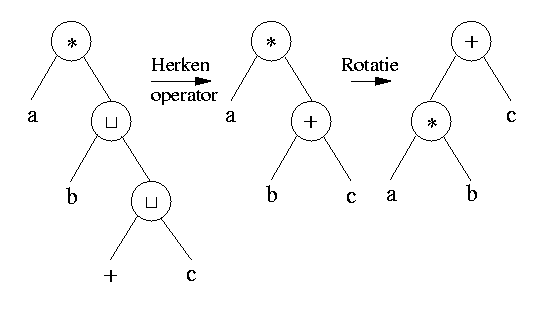
The method IdentifierView.splitme() is responsible for introducing Space operators when the typed Identifier is not valid as a single token (e.g. a* is split into a and *). Whenever splitme() inserts a Space operator, it calls the OperatorSpace.recognizeOp() method. This method checks if we can recognize a new operator with that fresh Space operator.
The InfixBinaryOp,
PrefixUnaryOp and
PostfixUnaryOp
classes each manage a list of operators. Given an identifier, they
can decide whether it is the name of an operator (isOperatorName()).
They can create an operator given its name (getInstance()).
Internally, this is done by associating a Factory class
with each operator name. This Factory class contains a single method
that returns an Operator object of the correct subclass of Operator.
For example, the
OperatorSpaceFactory
class returns OperatorSpace objects.
An alternative approach would be to use the Java
introspection
methods and throw away all Factory objects.
This is not implemented yet because I'm not sure whether Netscape
allows applets to do introspection.
The operator lists are built into the StandardOperators class. Introducing a new operator requires adding a line to this class. A more extensible way for introducing new operators is required.
As an example, let's look how a StackCanvas displays a Formula. When the user starts typing a fresh formula, StackCanvas.keydn() creates a new FormulaView (in the push() method). Since this is a Container, the StackCanvas can add it as a child and place it in the right position on the screen; the AWT and the FormulaView will take care of displaying the Formula.
The FormulaView manages a table linking each Part of the Formula to a Component. Initially, this table is empty. The FormulaView calls the createView() method of the root Part of the Formula. The result of this call is a Component, which is added to the table. Afterwards, the table is consulted, so that a certain Part can be sure that its createView() method will be called at most one time. We call the Part a Model (a datastructure representing some mathematical object, e.g. a multiplication operator) and its corresponding Component a View and Controller of that Model. We do not use separate classes for View (show a component on the screen) and Controller (intercept keyboard and mouse input and modify the Model accordingly), since the Component class does both; in the following, we shall use the word View also in the sense of a Controller.
Whenever the View receives user input, it can ask the Model to modify itself. For example, an IdentifierView that shows an Identifier iden asks the Model (the corresponding Identifier object) to change its string to ident when the user types a t keystroke by calling the setString() method of the Identifier. Note that the View does not change the View itself, but only the Model!
Each View object has an internal field containing its Model. In other words, the View is responsible itself for remembering what its Model is. When the View receives user input, it asks the Model to update itself.
Models (Parts) do not contain an extra field containing a list of their Views, the
idea of a Part being to represent the notion ``syntax tree'' as efficiently
as possible. It is clear that having extra data associated to each Part
is very unefficient in terms of memory when you only want to manipulate
formulas internally without displaying them.
Instead, the
formula.MVC
class contains a central table, where a Model can retreive its Views.
When a View wants to connect itself to a certain Model, it sets its
internal field (to remember its Model), and calls the
MVC.registerView() method, so that the Model can notify the View
later whenever it changes.
Each time the Model is changed, it calls MVC.changed(). This method calls the updateView() method of all Views that are linked to this Model. All Views have such an updateView() method, since they must implement the View interface. If necessary, the Model can supply an extra object containing details about the way the Model is changed. For example, a Matrix supplies a TabularModified object when a row or column is added or removed. The TabularModified object indicates precisely which row or column is affected, whether it was added or removed, and so on. The View can take advantage of this extra detail information to reflect the changes of the Model more efficiently.
A problem with this approach is that the central MVC table interferes with the Java garbage collecting scheme. Normally, when a View is not in use anymore, the Java virtual machine notices that no references to the View object exist, and frees its resources. The problem is that the MVC table always keeps a reference to the registered Views, so a View cannot be freed, unless MVC.unregisterView() is called explicitly. This boils down to having to manage resource freeing explicitly by the programmer, and that is precisely what the Java garbage collecting scheme wants to avoid. The solution for this problem is to use Java 2's weak references, but since most browsers still only implement Java 1.1, we have to delay the introduction of this feature to a later date.
A View can also decide to move the cursor to another View by calling the FormulaView.setCursorComp() method. Optionally, by supplying an extra integer argument, you can request the new View to try to place the cursor in a certain position (Somewhere_LEFT, Somewhere_RIGHT, and so on, or a number >=0 to indicate a View-dependent cursor position---e.g. in the case of an IdentifierView, the position of the letter next to which the cursor is to appear). A View can find out which FormulaView it is in by calling FormulaView.get().
Views can request to be notified whenever the cursor enters or leaves them (`becomes active/inactive') simply by implementing the ActivationListener interface. The deactivate() and activate() methods are called (by setCursorComp()) at the appropriate times (just before the View is about to be deactivated and just after the View has become active).
If the Component implements HasCursorPos, setCursorComp() calls the View's setCursorPos() method with an integer argument indicating the desired cursor position (Somewhere_LEFT etc). If you implement HasCursorPos, your setCursorPos() method should understand the standard Somewhere_xxx arguments. You may also accept values >=0 for View-dependent cursor positioning. If you do not understand a certain value, be sure to have some reasonable default action. The result of getCursorPos() is up to your own taste and is currently not used anywhere (*pending: check this*).
mousePressed() is called when the user pushes the mouse button on the View (i.e. before the mouse button is released). This method should return true when the View wants to handle mouse drags or false when the View does not handle drags. In the latter case, the system will start drawing a selection rubber band rectangle. An example of a View that handles mouse drags is the GraphView, where the user can drag arrows and vertices. The View is responsible for asking the AWT for mouse events during the drag.
mouseDown() is called when the user has clicked the left mouse button on the View, i.e. when the mouse button has been pressed and depressed. If the user pushes the right button, a popup menu is displayed and the mouseDown() method is not called.
The reason we do not use the AWT directly to fetch mouse events is that the FormulaView class does some manipulations with the mouse input. For example, when the user only drags a few pixels, this is interpreted as a mouse click and not a drag, since otherwise the mouse has to be held infuriatingly still to generate clicks :-)
We need a more flexible way to add new buttons to the popup menus.
E.g., when someone develops a proof generator, the code for the
ProofView
class has to be modified in order to add a "Generate Proof" menu.
We need some mechanism so that the proof generator can register itself
into a central database (essentially telling the system
``I'm a function that works on Proof objects'').
If two different packages define an operator with the same name, say gve.calc.formula.OperatorPlus and my.complex.OperatorAddition both define an operator called +, the system will have to choose one. We suggest the operator from the package imported first is chosen, so the order in which the user imports packages is important. If the user wants the other choice, he will have to type my.complex.+ for example. Maybe we also should allow shortcuts like formula.+ for gve.calc.formula.+ since the last form is rather cumbersome to type. We also need to investigate the parsing of identifiers like gve.calc.formula.+, since here the dots are operators and the + is an Identifier (the right argument of the rightmost dot operator), and the whole of this aggregate of dot-operators should ultimately be recognized as one single Identifier.